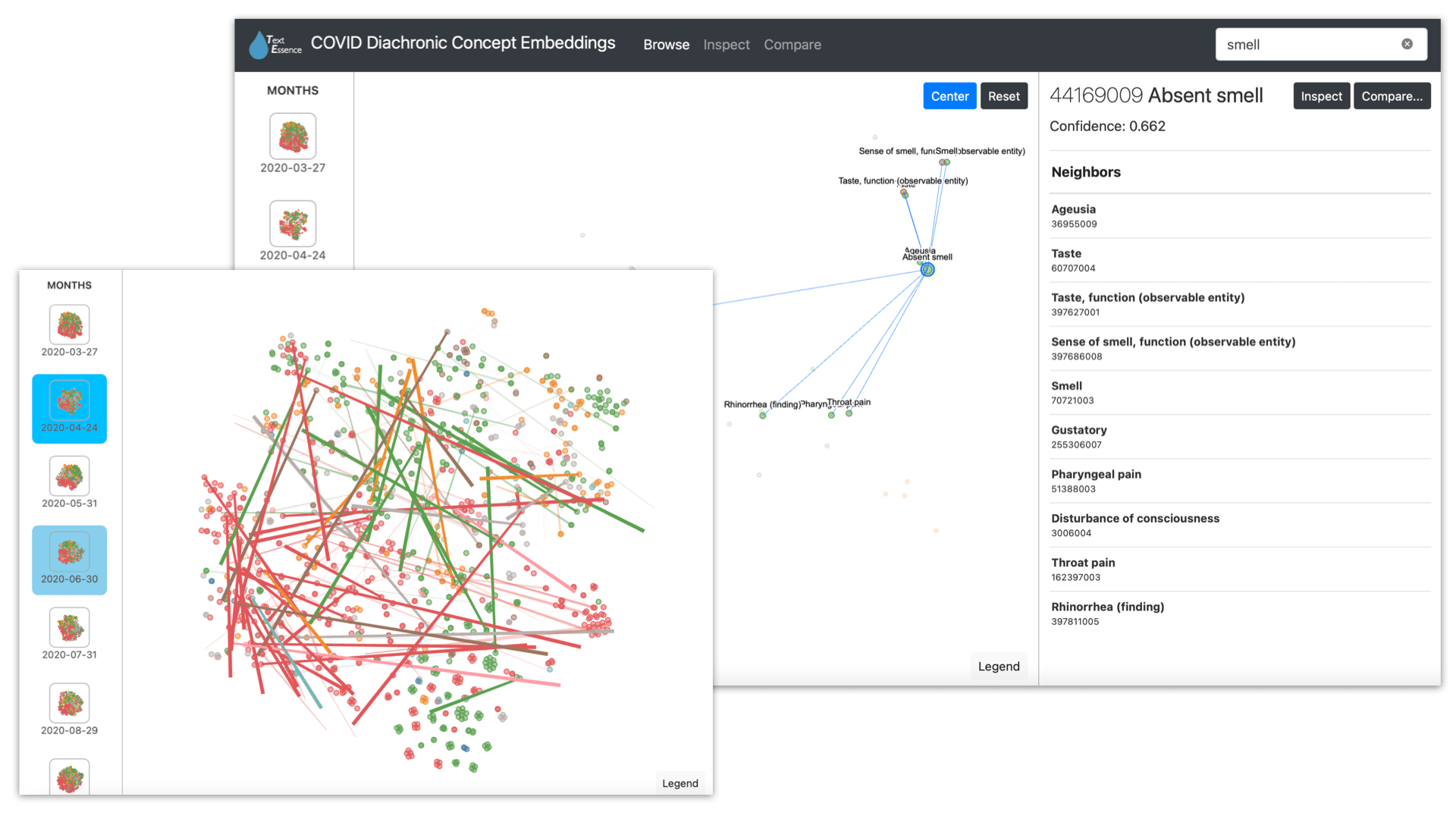
TextEssence is a tool for comparative text analysis.
Word embeddings capture patterns in how words are used in collections of text. Concept embeddings do the same for knowledge base concepts.
TextEssence lets you examine the differences between different sets of embeddings, to see what they capture about different corpora.
- Train word and concept embeddings on any corpus, no annotations required.
- Compare differences in embedding nearest neighbors between different corpora.
- Visualize changes in the organization of embedding spaces from different corpora.
Read the Paper
Denis Newman-Griffis, Venkatesh Sivaraman, Adam Perer, Eric Fosler-Lussier, Harry Hochheiser. TextEssence: A Tool for Interactive Analysis of Semantic Shifts Between Corpora. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Read it on ACL AnthologyInterface
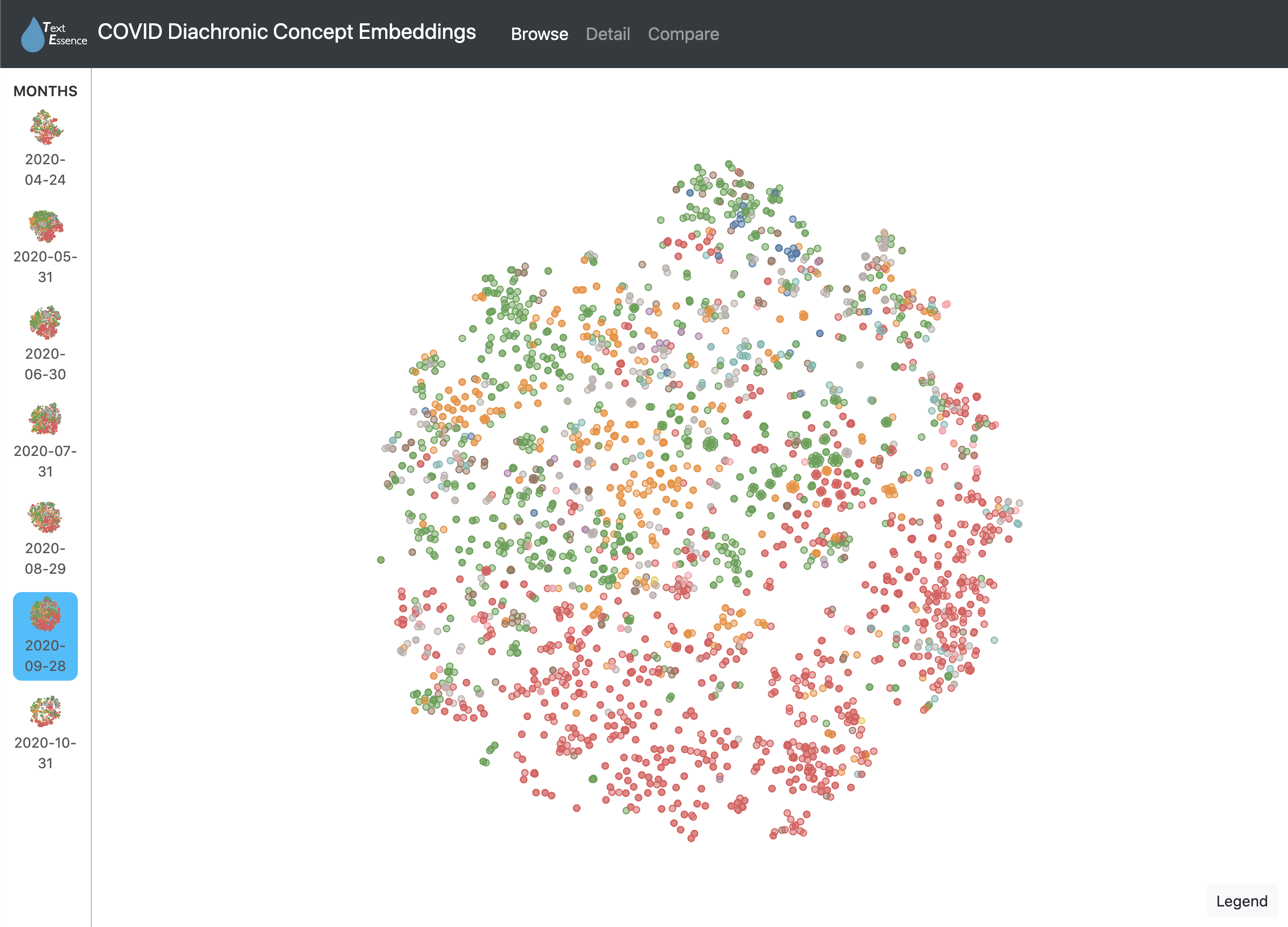
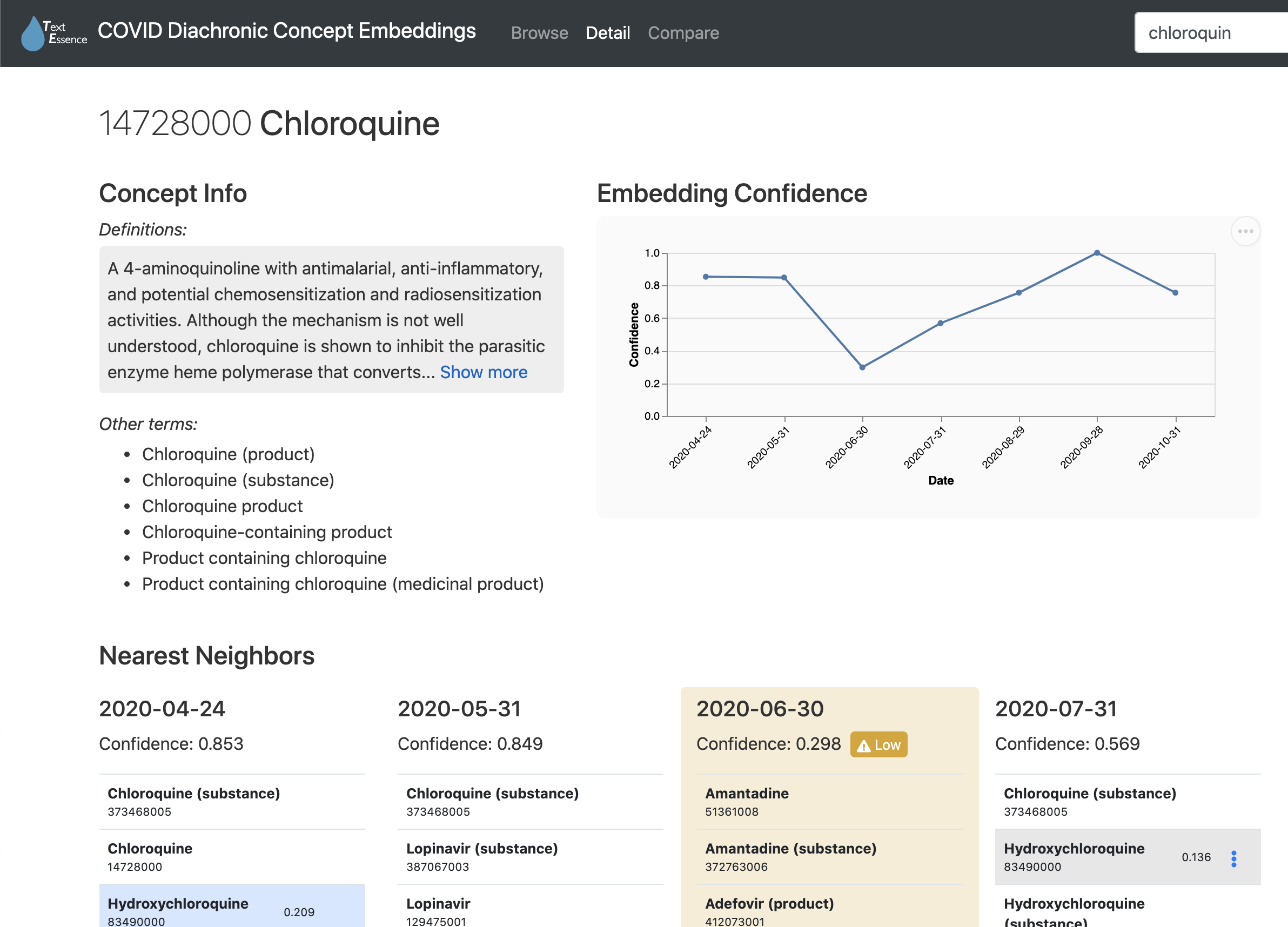
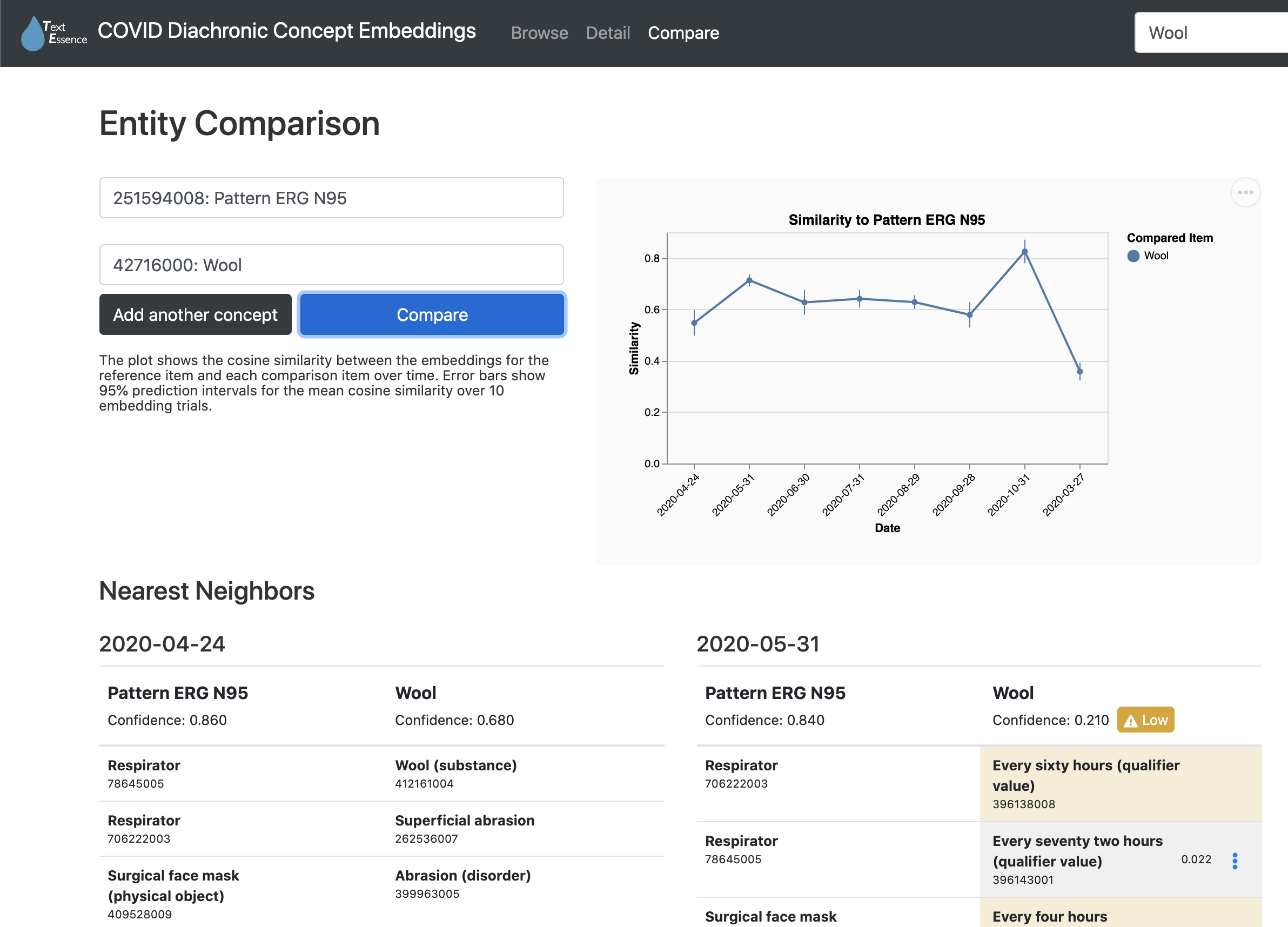
The web interface for TextEssence has three components:


Sponsors
Computational resources were provided by the Ohio Supercomputer Center.
TextEssence was supported by the National Library of Medicine of the National Institutes of Health under award number T15 LM007059
